|
ЖЃЖЃ...
ЧхДрЕФЮЂаХЩљЃЌАбЮвДгУЮжаЛНабЁЃдчвбЯАЙпЦ№ДВжЎКѓЃЌЛиИДЯТЙЋжкКХаХЯЂЃЌХРвЛЯТЮЂаХШКРяЕФТЅЁЃ
жЛЪЧНёЬьЃЌЬиБ№ШШФжЁЃКьЩЋЕФаЁдВЕуЃЌвбОЬсЪОЃЌЮЂаХШКга 128+ ЕФЮДЖСЯћЯЂСЫЁЃ
КУЦцДђПЊСЫЯТЃЌетДЮЬжТлЕФЃЌЪЧвЛЕР SQL УцЪдЬтЁЃ

ЮвЖдДњТыгаНрёБЃЌПДЕНХЄФѓГЩвЛлчЕФ SQL, ШЬВЛзЁФУЕН Visual Studio Code РяЃЌгУ poorman's sql formatter Иј PS ЯТЁЃ
ОЭЯёЗЂХѓгбШІЃЌШЮКЮВЛОТЫОЕЃЌУРбеЕФЭМЃЌДгВЛЗЂЁЃХЎКЂзгУЧЖМЖЎЕФЃЁ
вдЯТЪЧећРэКѓЕФДњТыЃЌбежЕИпКмЖрЃК

УцЪдЙйЬсЮЪЃЌАбЕквЛЖЮ SQL ИФЮЊЕкЖўЖЮКѓЃЌЮЊЪВУДадФмЛсгаШчДЫжЎДѓЕФЬсИпЃЌгХЛЏТпМЪЧЪВУДЁЃ
етвЛЬтЃЌШУЮвЯыЕНЬиБ№ЖёЖОЕФвЛИіЖЮзгЃК
ФудИвтЬЩдкБІТэГЕРяПоЃЌЛЙЪЧЯВЛЖзјдкздааГЕЩЯаІЃП
УЛгаЯоЖЈЕФЬѕМўЃЌЛиД№здШЛЧЇЦцАйЙжЃЌЩѕжСДѓЯрОЖЭЅЁЃ
ШчЙћгаЬѕМўЃЌЮЊЩЖЮвВЛФмЬЩдкБІТэРяаІЃЛгжЛђепзјдкздааГЕЩЯЃЌФбЕРОЭВЛЛсПоСЫЃП
ЛузмСЫЯТЃЌДѓМвЖдетЕРЬтЕФгХЛЏТпМЃК
-
-
user БэЩЯга age ЕФЫїв§ЃЌЛЙга id ИВИЧЫїв§
-
-
ЕквЛЖЮ SQL жДааСЫШЋБэЩЈУш
ИќгаХѓгбжЪвЩСЫЕкЖўЖЮЕФадФмЬсИпЃК
-
УЛга order byЃЌНсЙћТвађЃЌвзВњ bug
-
ЕквЛЖЮ SQL жиХмЯТЃЌгІИУ 0 УыОЭГіНсЙћ
-
Г§ЗЧЪЧВщбЏЛКДцЃЌЕкЖўЖЮаЇТЪЮДБиИп
-
MySQLгХЛЏЦїецБПЃЌЮЊЪВУДВЛжБНгЬјЕНЕк 100000 ЬѕЃЌАзАзРЫЗбЖСШЁФЧУДЖрЪ§Он
ЛиД№ЖМКмОЋВЪЃЌжЪвЩвВЖМгаРэгаОнЁЃПЩвдПДЕУГіРДЃЌФмЛиД№ГівЛЖўЕФХѓгбЃЌЪ§ОнПтЙІЕзЖМКмАєЁЃ
ВхвЛОфЃКУЛгаЛљДЁЕФаЁАзЃЌФуПЯЖЈКмЗГЬжТлетбљЕФЮЪЬтЁЃетОЭЪЧЮЊЪВУДЃЌЮвЕФШКРяЃЌЖСепЖМашвЊгаЛљДЁЁЃЕБШЛЃЌФуШєецИааЫШЄЃЌЬЌЖШгбКУЃЌгаПХЧѓжЊКьаФЃЌФЧЗЧГЃЛЖгФуЁЃ
ЛиЕНЬтФПЩЯРДЃЌвЊЛиД№КУетЕР SQLЃЌЬиБ№ПМбщЪ§ОнПтЕФЕзВуШЯжЊЁЃНіНіДггяЗЈНЧЖШЃЌетвЛЬтВЛФбЃЌЮоЗЧЪЧзгВщбЏ + inner join ЕФПМВьЁЃ
ДгЪ§ОнПтЬхЯЕНсЙЙЩЯЛиД№ЃЌетвЛЬтОЭБШНЯИДдгЁЃЛЙвЊПМТЧЕН MySQL ЕФВњЦЗЬиадЃЌБШШч MySQL 8 , гааЉЙиЯЕаЭЪ§ОнПтЕФРэТлЃЌдкетРяОЭааВЛЭЈЃЌБШШчВщбЏЛКДцЁЃ
ОнЮвгаЯоЕФШЯЪЖЃЌетЕРЬтПМВьСЫетаЉЗНУцЃК
дкМЬајдФЖСжЎЧАЃЌЧыИїЮЛПДЙйЃЌздБИЧхВшЛђПЇЗШЃЌвдУтЖСЕНИЩПЪЖјЗХЦњЁЃзМБИКУСЫЃЌдлУЧОЭПЊЪМЁЃ
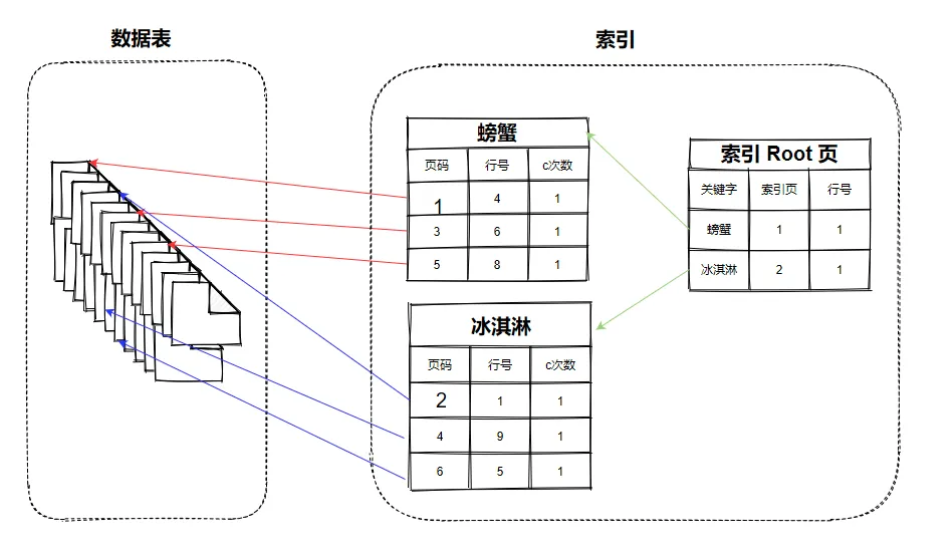
Ъ§ОнПтЕФЪ§ОнвГНсЙЙ
Ъ§ОнвГЪЧЪ§ОнПтЕФЕзВуДцДЂЕЅдЊЁЃЮвжЊЕРЃЌКмЖрГѕбЇепЬ§ЕНЕзВуЃЌОЭЭЗДѓЁЃШЯЮЊКЭ c/c++ вЛбљЮоСФЃЌЩѕжСЯёЪЧПДЕНСЫЛуБрЃЌЬьШЛЯызХвЊЬгБмЁЃ
ЮвдјОвВетбљЁЃЩѕжСЛУЯыЃЌЯёащжёвЛбљЃЌЭЗЖЅЭЗЃЌЛёШЁЮобТзгвЛМззгЙІСІЁЃЕЋППYYЃЌНтОіВЛСЫШЮКЮЪЕМЪЮЪЬтЁЃДПППгыЪ§ОнПтДѓVЃЌЮеИіЪжЃЌКШИіПЇЗШЃЌЪЧВЛЛсЛёЕУШЮКЮММЧЩЕФЁЃ
НгЪмСЫетИіЪТЪЕЃЌЮвОЭПЊЪМЫРПФЪаУцЩЯФмТђЕНЕФЪ§ОнПтЯрЙиЪщМЎСЫЁЃ
гкЪЧЮвЗЂЯжЃЌЪ§ОнПтЕФЪ§ОнвГНсЙЙЃЌВЂЗЧЯыЯѓЕФФЧУДФбЁЃгУзївЕБОРДБШгїЃЌОЭКмКУРэНтЁЃ
аЁЪБКђаДзївЕЃЌДѓМвЖМгУЕФБОзгЃЌгІИУЖМЛЙгЁЯѓЭІЩюАЩЁЃ
ЬязжИёгяЮФБОгыЪ§бЇгУзївЕБО
 етжжБОзгЕФУПвЛвГЃЌЖММЧдизХЮвУЧФбЭќЕФЭЏФъЁЃ
етжжБОзгЕФУПвЛвГЃЌЖММЧдизХЮвУЧФбЭќЕФЭЏФъЁЃ
гаБЛЗЃГСєЯТЕФПЮЮФЖЮТфЃЛвВгае§ЖљАЫОаДЯТЕФзїЮФЃЛЛЙгааДЕФаЁжНЬѕЃЌЭЈГЃФЧвЛвГаДЩЯвЛСНОфОЭЫКСЫЃЌЯждкЯыЯыЙЛРЫЗбАЩЁЃ
дкетбљЕФБОзгРяаДзжЃЌФуаДЕУзжДѓЃЌЛЙЪЧаЁЃЛЛђепаДвЛааПевЛааЃЌЖМЛс гАЯьетвЛвГЕФаХЯЂУмЖШЁЃУїУїПЩвдгУвЛвГжНаДЭъЃЌаДЕФзжЖљДѓСЫЃЌаДЕФЯЁЪшСЫЃЌаагыаажЎМфЛЙгаПевЛСНааЃЌОЭЛсМгДѓаХЯЂУмЖШЕФМфЯЖЁЃ
Ъ§ОнПтЕФЪ§ОнвГвВвЛбљЁЃЫќДгЩЯЕНЯТЃЌаДТњСЫbyteЃЈзжНкЃЉЃЌЛђепЮЊСЫ insert ЫйЖШКЭМѕЩйаавчГіЃЌжаМфПеМИааЁЃ
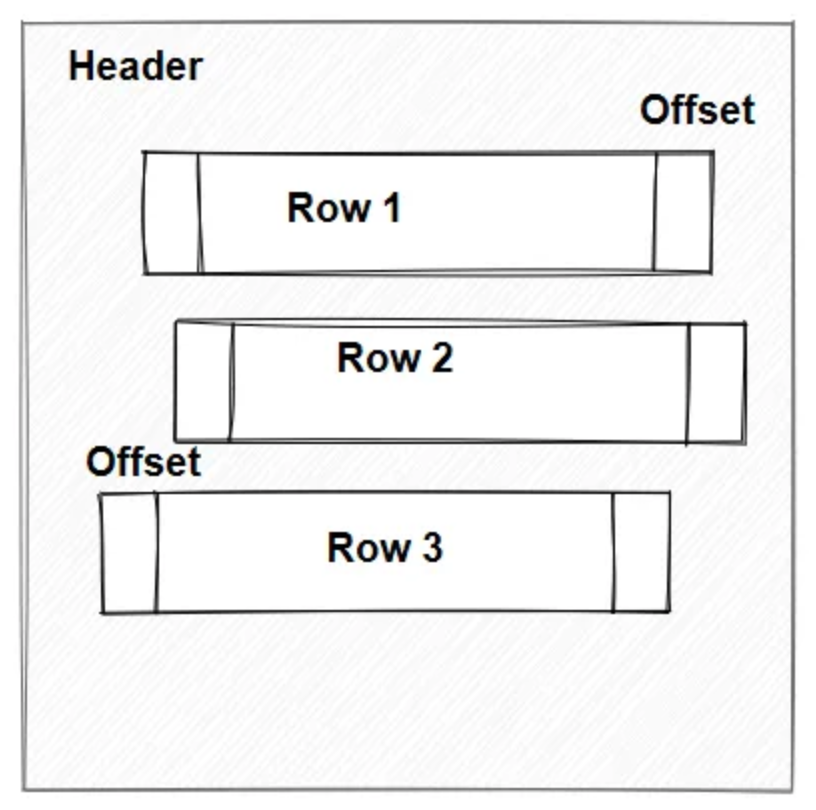
етбљЕФЪ§ОнвГЃЌзщКЯЦ№РДЃЌОЭГЩСЫДцДЂвЛеХБэЕФНсЙЙЁЃЪ§ОнСПдНДѓЃЌЪ§ОнвГвВдНЖрЁЃ
ШчЙћУЛгаКмКУЕФЩшМЦзжЖЮГЄЖШЃЌДцДЂЕФЪБКђЃЌвВУЛгаАВХХЕФНєУмаЉЃЌФЧУДдБОДцДЂ1ЭђааЕФЪ§ОнЃЌОЭгаПЩФмашвЊ10ЭђааЕФПеМфЁЃ
ЩЯСНЭМОЭКмКУЕФНтЪЭСЫЃЌПеМфАВХХЕФживЊадЁЃ
етКЭдкзївЕБОЩЯаДзївЕвЛИіЕРРэЁЃ
аДзївЕНВЭъСЫЃЌЮвУЧРДНВНВЖСЁЃ
ШчЙћФуДђЫуДгЭЗЕНЮВШЅЖСФуЕФзївЕБОЃЌЯыБиЛсЛЈКмЖрЪБМфЃЌВХФмевЕНФуЯывЊЕФдјОаДЙ§ЕФЬиБ№ХхЗўздМКЕФФЧЖЮЛА,ЛђепЙЋЪНЭЦРэЁЃ
ДЫЪБЃЌгаСНжжЗНЗЈЃЌПЩвдАяФуЃК
вЛжжЃЌвЛПЊЪМаДзївЕЃЌОЭАбзжЖљаДЕУаЁвЛаЉЃЌАбПеааЖМаДЩЯзжЖљЃЌетбљАб 14 вГЕФзївЕБОЃЌХЈЫѕГЩ 2 вГЃЌздШЛЗЕФвГЪ§ЩйСЫЃЛ
ЖўЪЧЃЌСэЭтФУвЛИіБОзгЃЌАбУПвГЕФЙиМќзжМЧЯТРДЃЌБШШчѓІаЗдкЕк1ЃЌ3ЃЌ5вГЃЛБљМЄСмдкЕк2ЃЌ4ЃЌ6вГЃЛгЮЯЗЛњдк7ЃЌ8ЃЌ9вГЁЃетбљЃЌевЦ№РДОЭЩйЗМИвГЁЃ
ДЯУїШчФуЃЌЖСЕНетРяЃЌвЛЖЈЯыЕНаЉЪВУДЁЃУЛДэЃЌЕквЛЖЮ SQL КЭЕкЖўЖЮ SQLЃЌдкУЛгаЫїв§ЕФЧщПіЯТЃЈМйЩшФуУЛгаЫїв§ЕФИХФюЃЉЃЌФЧУДЕкЖўжжаДЗЈЃЌЗДЖјИќТ§вЛаЉЁЃ
ДѓМвЖМЪЧдкбАев age=10 ЕФЪ§ОнЃЌЖјЕкЖўЖЮSQLЃЌевЭъжЎКѓЃЌЛЙвЊдйевет 10 ЬѕЪ§ОнЫљдкЪ§ОнвГЩЯЕФЦфЫћЪ§ОнЁЃ
ЯрЕБгкЃЌФуЗБщзївЕБОЃЌКУВЛШнвзевЕНФуЯыЕНЕФФЧЖЮЛАЃЌКЭЪ§бЇЙЋЪНЃЌЗЂЯжРЯЪІЛЙвЊЧѓФуАбФЧвЛвГЩЯЕФЦфЫћЖЮТфЛђепгІгУР§згЃЌЖМевГіРДЁЃетбљФуашвЊжиИДШЅЖСЃЌКФЪБЛсИќЖр
ЪТЪЕЩЯЃЌОЙ§ЪЕбщЃЌвВЕФШЗШчДЫЁЃ
дк MySQL 5.5 жаЃЌemp_info га588ЭђЪ§ОнЃЌУЛгаШЮКЮЫїв§КЭжїМќЁЃ
етЖљЃЌЮвгУ employees ПтДњЬцЁЃЮвВЂУЛгадЮЪЬтвЛФЃвЛбљЕФЪ§ОнЁЃ

ЯИаФЕФХѓгбЛсЗЂЯжЃЌСНЖЮ SQL жаЖММгСЫ SQL_NO_CAHE. етЪЧЮЊСЫЗРжЙ Query Cache ЕФЗЂЩњЃЌдіМгЫЕЗўСІЁЃMySQL 5.6 МАвдЯТАцБОЖМжЇГж Query Cache, вВОЭЪЧВщбЏЛКДцЁЃ
НтЪЭЯТЮЊЪВУДвЊЩшМЦ Query Cache.
ЕБЖўЖЮ SQL вЛФЃвЛбљЃЌСЌајжДааСНДЮЪБЃЌЕкЖўДЮВщбЏКФЪБЮЊ0. етЪЧвђЮЊЃЌгХЛЏЦїГфЗжРћгУЕквЛДЮЕФЛКДцЪ§ОнЃЌУыГіНсЙћЁЃ
етЪЧдѕУДзіЕНЕФЃП
МђЕЅРДЫЕЃЌЕквЛДЮжДааЕФФГЬѕ SQL ЛсБЛгХЛЏЦїБрвыЮЊвЛЖЮ hash ЮФБОЃЌЧвЫќЕФжДааНсЙћЃЌЛсБЛДцДЂдкФкДцжаЁЃ
ЕБвЛФЃвЛбљЕФ SQL дйДЮЗЂЫЭЕНгХЛЏЦїЪБЃЌЛсКЭДцДЂЕФ hash жЕзіИіЖдБШЃЌШчЙћвЛбљЃЌОЭжБНгЗЕЛиФкДцжаЕФНсЙћЃЌЖјВЛашвЊдйДЮжДааЁЃ
етЙІФмЃЌЯыЯыЖМаЫЗмЁЃЕЋЃЌвВгаБзЖЫЁЃФмжиИДРћгУЛКДцЃЌБиаыЪЧЕзВуЪ§ОнУЛгаБфЛЏЃЌвЛЕЉБфЛЏСЫЃЌФЧУДНсЙћОЭЛсВЛЖдЃЌЖдгкЕкЖўДЮЗЂЫЭ SQL УќСюЕФгУЛЇРДЫЕЃЌОЭВњЩњСЫЪ§ОнВЛвЛжТЁЃ
дквЛИіЗЧГЃЗБУІЕФ OLTP гІгУжаЃЌЪ§ОнИќаТГіКѕФуЯыЯѓЕФПьЃЌВщбЏЛКДцЭљЭљЧъПЬМфОЭЛсЪЇаЇЁЃгыЦфЮЌЛЄетУДЖЮЪЇаЇЕФФкДцЃЌВЛШчВЛЮЌЛЄЃЌПеГіРДИЩЕуБ№ЕФЪТЃЌЖрКУЁЃ
гкЪЧ MySQL 8 ОЭЗЯЦњСЫЫќЁЃ
дкБОР§жаЃЌМгЩЯ SQL_NO_CACHE етбљЕФ hint КѓЃЌОЭЪЧвЊХХçОгУВщбЏЛКДцДјРДгХЛЏЕФПЩФмЁЃетбљЃЌУПДЮжДааЖМжиаТзпвЛБщНтЮіЃЌгХЛЏЕНШЁЪ§ЁЃБЃжЄЪЕбщЕФЙЋЦНадЁЃ
ЮвАбет 588ЭђЪ§ОнЃЌЕМШы MySQL 8 АцБОжаЃЌЭЌбљжДааЩЯУцЕФ SQLЃЌЦцМЃОЭРДСЫЃК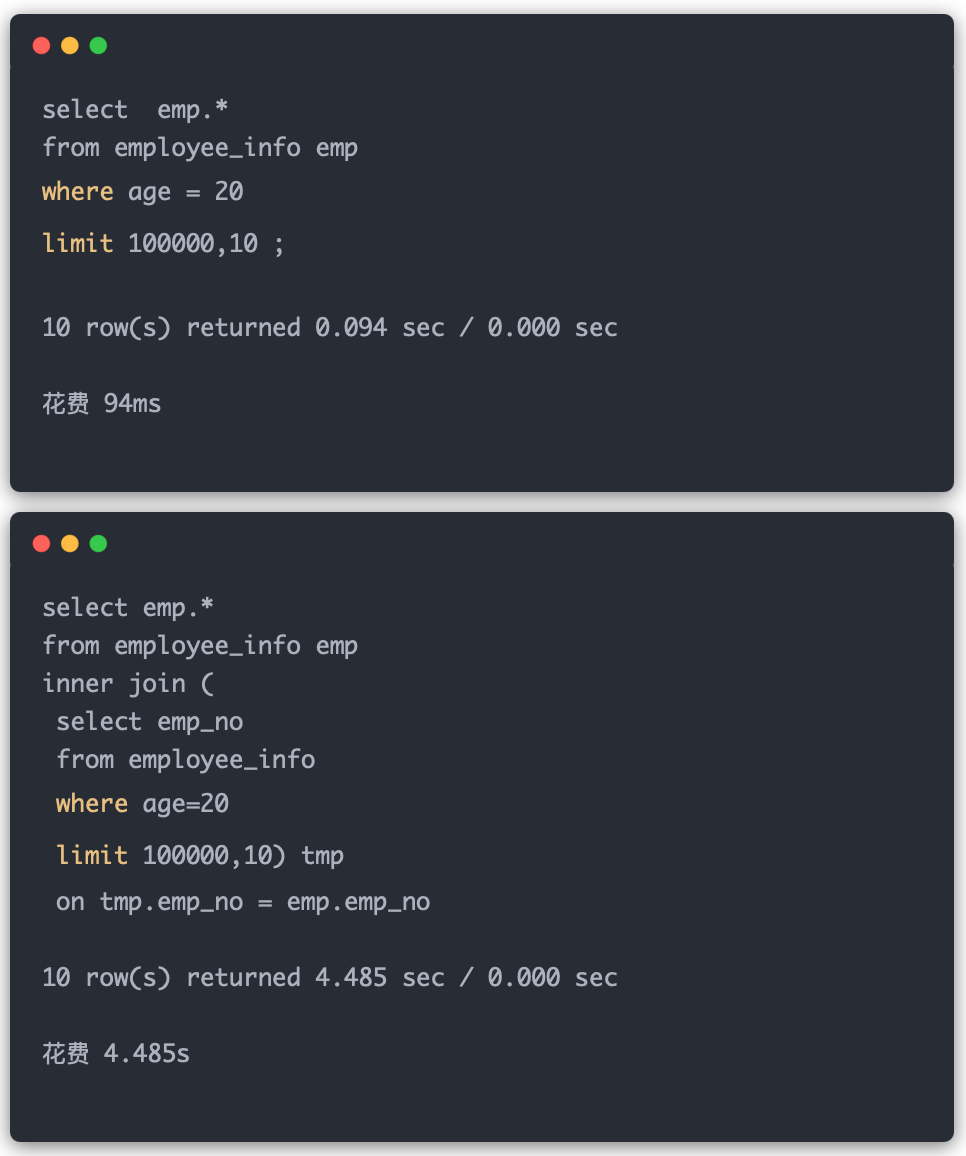
УЛЯыЕН MySQL 8 дкФЌШЯХфжУЯТЃЌБШ MySQL 5.5 ЛЙ “НЁЭќ”ЁЃЗЙ§ЕФзївЕЃЌОгШЛвЛЕуЖМВЛМЧЕУЁЃ
ПДжДааМЦЛЎжЊЯўЃЌзгВщбЏКЭЭтВуВщбЏЃЌЫфШЛЗУЮЪЭЌвЛИіБэЃЌЕЋШДЕБГЩСНИіБэРДДІРэЁЃ
жСДЫЃЌДѓМвПЩвдЧхГўЕФПДЕНЃЌЕкЖўжж SQL ВЛОгХЛЏЃЌадФмЛЙВЛШчЕквЛжжаДЗЈЁЃ
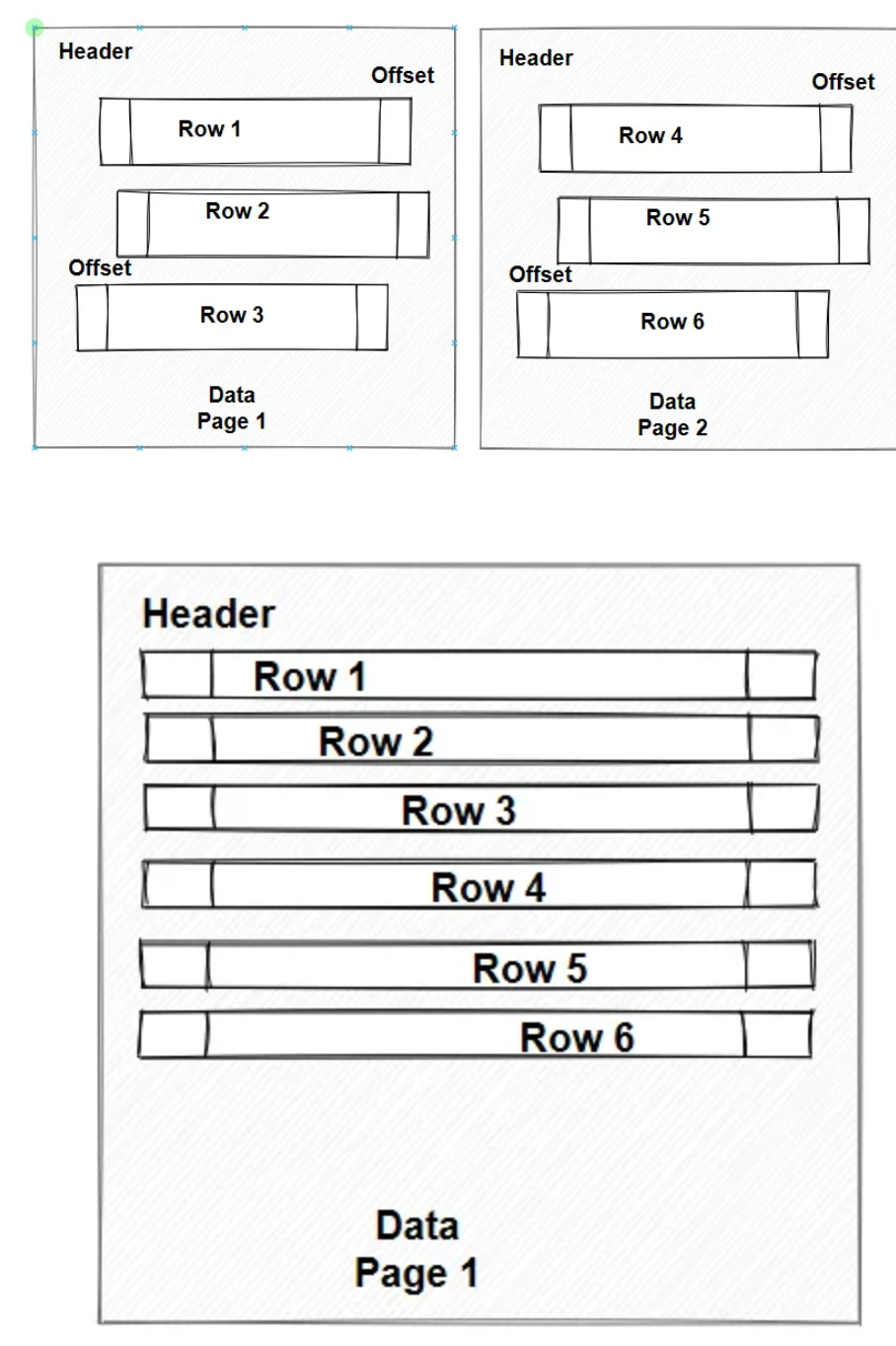
Ъ§ОнПтЕФЫїв§вГНсЙЙ
ИеИеЃЌдкНВЪіЬсИпВщбЏаЇТЪЕФЪБКђЃЌгУЕНСЫ 2 ИіЗНЗЈЁЃетСНИіЗНЗЈЃЌдкЪ§ОнПтжаЃЌгУЫїв§РДЪЕЯжСЫЁЃ
МйЩшЃЌдкзївЕБОЩЯЃЌУПвЛвГЖМаДСЫвЛЦЊаЁЩЂЮФЁЃЮвгУСэЭтвЛИіБОЖљЃЌАДееЙиМќзжЃЌМЧТМетаЉЙиМќзждкзївЕБОжаЖдгІГіЯжЕФвГТыКЭааКХЃК
ѓІаЗЃК
БљМЄСмЃК
гкЪЧЃЌдБОАДееДгзївЕБОЃЌвЛвГвГбАевѓІаЗЃЌашвЊЗЭъЫљгавГЃЌВХФмевШЋЃЌЯждкгаСЫЫїв§БОЃЌвЛвГ3ааЃЌОЭИуЖЈЁЃ
ЛиЕНУцЪдЬтРДЃЌПДЕкЖўЖЮ SQLЃЌвЊев100010 ааЪ§ОнЃЌдкЫїв§жаевЃЌКЭдкШЋБэжаевЃЌЯћКФЕФЪБМфЃЌОЭВЛдкЭЌвЛИіЪ§СПМЖСЫЁЃ
ОпЬхРДЯИЫЕЁЃ
дкзївЕБОЩЯЃЌаДЕФаЁзїЮФЃЌГ§СЫѓІаЗЃЌБљМЄСмЕШЙиМќзжЃЌПЯЖЈЛЙгаКмЖрКмЖрЦфЫћДЪЛуЃЌБШШч"аЁУУЩњШеФЧЬьЃЌЮвЫЭИјЫ§ 2 КаБљМЄСшЃЌ6 жЛѓІаЗЃЌЛЙга 10 ЖрУЕЙх"ЁЃ
етбљвЛРДЃЌвЛвГЩЯжЛГіЯжвЛИіѓІаЗЃЌЗЭъећИіБОЖљЃЌВХжЊЕРга 5 вГЪЧАќКЌѓІаЗСНзжЕФЁЃ
ФЧ user етеХБэЃЌвВвЛбљЃЌПЩФмга 10 ИізжЖЮЃЌУПИіЪ§ОнвГФмДцЩЯ 100 ЬѕЪ§ОнЃЌЖјУПЙ§ 10 вГЃЌВХгавЛИі age=20 ЕФгУЛЇЃЌФЧУД 100000 ЬѕЪ§ОнЃЌПЩФмОЭБЛЯЁЪЭдк 1000000 ИіЪ§ОнвГжаЁЃ
ЕЋЫїв§вГОЭВЛвЛбљСЫЃЌ100000 Иі age=10, ОЭдк 100000ааЩЯЃЌУПИіЫїв§вГФмДц 1000 ЬѕЃЌФЧУД 1000 вГЫїв§вГвВОЭДцЭъСЫЁЃ
ЭЈЙ§ЖдБШЃЌжСЩйга 1000000/1000 МД 1000 БЖЕФЪБМфНкЪЁСЫЁЃ
вдЩЯжЛЪЧМйЩшЃЌецЪЕЧщПіЃЌвЊИДдгЕФЖрЁЃ
гаЫїв§ЕФЕиЗНЃЌВЂВЛМђЕЅЁЃвђЮЊЫїв§зюДѓЕФЗчЯеЃЌдкгкЛиБэЁЃ
ЪВУДЪЧЛиБэЃП
ИљОнЙиМќзж"ѓІаЗ"ЃЌШЅевФФвЛвГГіЯжЙ§ЫќЃЌетЪЧЫїв§ИЩЕФЛюЁЃЕЋвРОн"ѓІаЗ"етИіЙиМќзжЃЌНјвЛВНевЕНзїЮФжаЕФжїНЧЃЌБШШч"аЁУУ"ЃЌФЧЫїв§ОЭзіВЛЕНСЫЁЃжЛФмЗПЊзївЕБОЃЌШЅУПвЛвГАќКЌ"ѓІаЗ"ЕФзїЮФжаЃЌШЅевЁЃетжжЧщПіЃЌОЭЪЧЛиБэЁЃ
ПЩМћЃЌЛиБэгждіМгСЫвЛДЮВйзїЃЌЛсдіМгКФЪБЁЃ
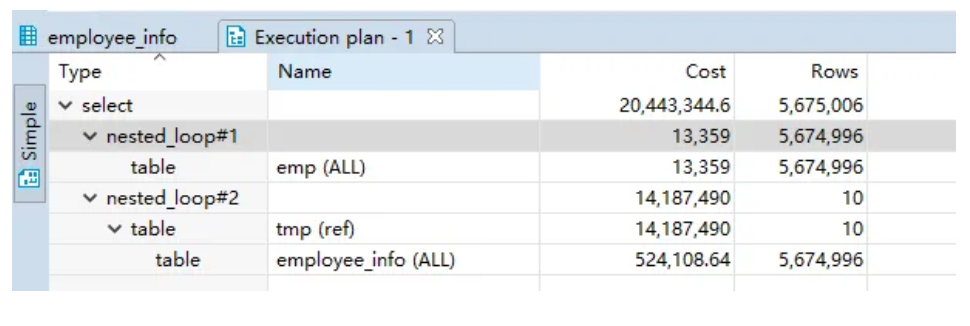
ЖјЕквЛЖЮ sql, БШЦ№ЕкЖўЖЮЃЌдіМгСЫЛиБэЕФДЮЪ§ЁЃвђЮЊВЂУЛжИЖЈАДееЪВУДШЅХХађЃЌетОЭЪЧгХЛЏЦїУЌЖмЕФЕиЗНСЫЁЃМйШчМгЩЯАДее id ХХађЃЌОЭКЭЕкЖўЖЮвЛбљСЫЁЃ
ОйИіР§згЃК

ПДРД MySQL 5.5 гХЛЏЦїдкетРязіСЫХаЖЯЃЌвд age ЮЊХХађЃЌетбљзюДѓЕФЯћКФдкЫїв§ЗУЮЪЩЯЁЃ
МйЩшвЊвд employees_info ЦфжаСэЭтЕФ from_date РДХХађЃЌПДЯТНсЙћЃК

етбљвЛРДЃЌВЛНіНівЊАбЫїв§ age=20 ЕФЪ§ОнШЋВПевБщЃЌЛЙашЛиБэзЅЯТ from_date ЕФжЕЁЃетОЭЪЧЛиБэЕФДњМлЁЃ
дк MySQL 8 ЩЯЃЌетЖЮ SQL вбОЮоЗЈХмСЫЃЌ52s ВХГіНсЙћЁЃ
ЛиЕНаДЗЈЕФЖдБШЩЯРДЃК

БШЦ№ 63ms, Пь1БЖЁЃ
гкЪЧЃЌЕкЖўжжаДЗЈЃЌдкгаЫїв§ЕФЧщПіЯТЃЌгХЪЦОЭРДСЫЁЃ
ЮоТлдк MySQL 5.5 ЛЙЪЧ MySQL 8, ЕкЖўжжаДЗЈЃЌЖМОпгаадФмгХЪЦЁЃ
ЕЋЪЧЃЌетЕРЬтЃЌЪЧОпгаЦчвхЕФЁЃУЛга Order By, Limit ЕФвтвхдкетСНжжаДЗЈжаЃЌОЭВЛЭЌЁЃ
ИФГЩетбљЃЌОЭгаЖдБШадСЫЃК
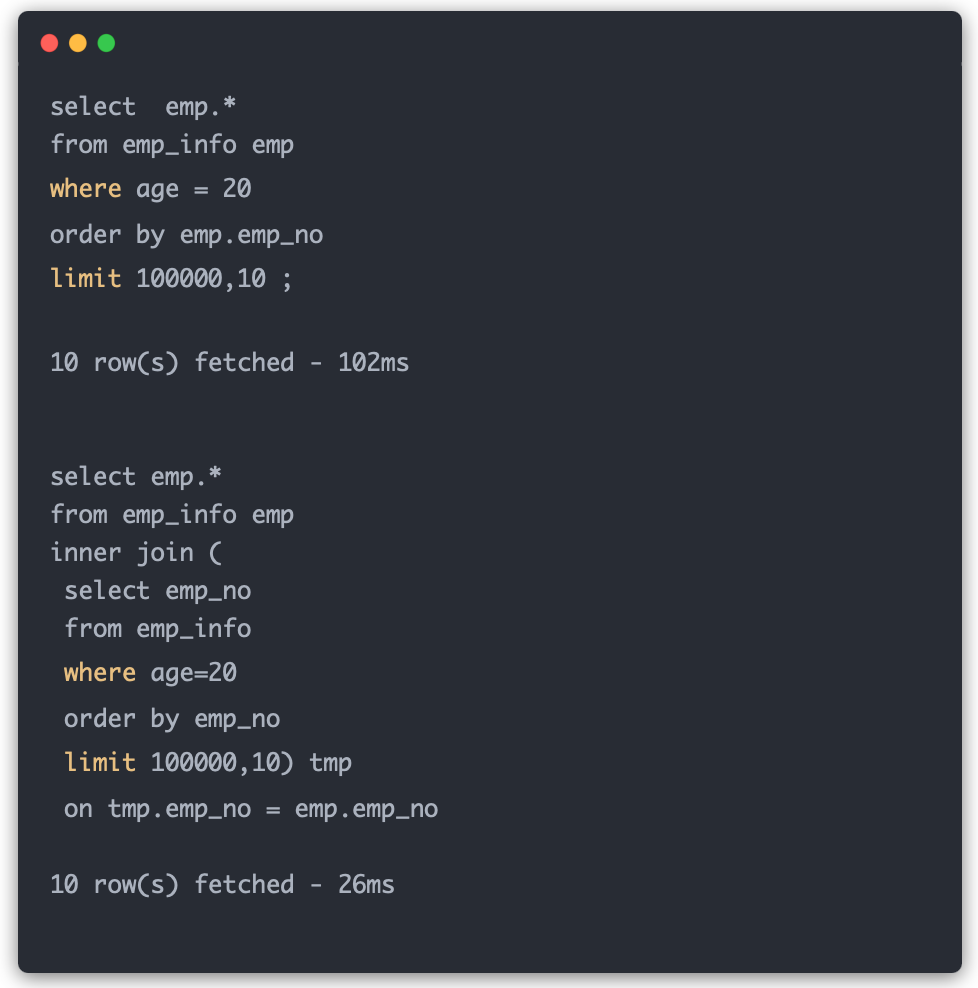
етбљЃЌЕкЖўЖЮ SQL ЕФгХЪЦВХФмЫЕЕУЧхГўЁЃЯраХПДЭъЩЯУцЕФНтЪЭЃЌдРэОЭКмЧхЮњСЫЁЃ
ЕЋетРяЛЙЩцМАЕНгХЛЏЦїЕФГЩБОФЃаЭМЦЫуЃЌЮЊЪВУДЕквЛЖЮ SQL УЛгаБЛгХЛЏЃЌПДЩЯШЅЗХЦњСЫЫїв§ЃЌЖјВЩгУСЫШЋБэЩЈУшЃП
ЯТЛидйНВЃЁ

| 

