1. ИХЪі
1.1 гІгУГЁОА
дкдкЙЙНЈЪ§ВжКЭжаМфПтЪБЃЌШчЙћЦѓвЕвЕЮёЪ§ОнСПМЖНЯДѓЃЌПЩФмЛсУцСйвдЯТЮЪЬтЃК
- ШчЙћЪЙгУЪ§ОнЭЌВНХњСПЖЈЪБЭЌВНЃЌЪ§ОнКмФбзіЕНИпадФмЕФдіСПЭЌВНЁЃ
- ШчЙћЪЙгУЧхПеФПБъБэдйаДШыЪ§ОнЕФЗНЪНЃЌУцСйФПБъБэвЛЖЮЪБМфВЛПЩгУЁЂГщШЁКФЪБГЄЕШЮЪЬтЁЃ
вђДЫЯЃЭћФмдкЪ§ОнПтЪ§ОнСПДѓЛђБэНсЙЙЙцЗЖЕФЧщПіЯТЃЌЪЕЯжИпадФмЕФЪЕЪБЪ§ОнЭЌВНЁЃ
1.2 ЙІФмЫЕУї
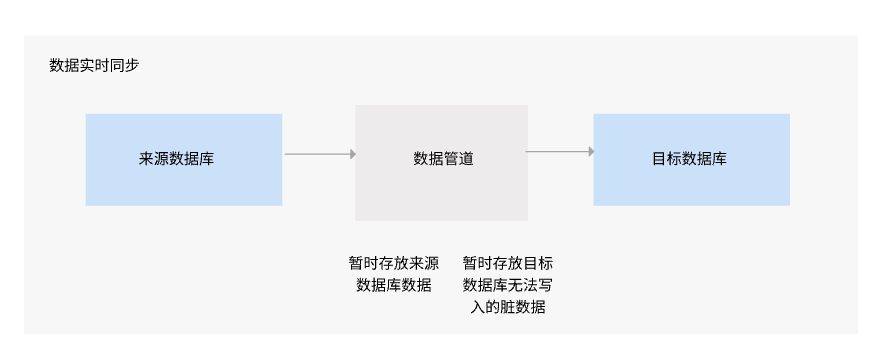
FineDataLinkМрЬ§Ъ§ОнЙмЕРРДдДЖЫЕФЪ§ОнПтШежОБфЛЏЃЌРћгУKafkaзїЮЊЪ§ОнЭЌВНжаМфМўЃЌднДцРДдДЪ§ОнПтЕФдіСПВПЗжЃЌНјЖјЪЕЯжЯђФПБъЖЫЪЕЪБаДШыЪ§ОнЁЃ
жЇГжЖдЪ§ОндДНјааЕЅБэЁЂЖрБэЁЂећПтЪ§ОнЕФЪЕЪБШЋСПКЭдіСПЭЌВНЃЌПЩвдИљОнЪ§ОндДЪЪХфЧщПіЃЌХфжУЪЕЪБЭЌВНШЮЮёЁЃ